
MySQL-01
理论基础与索引概念 - 详细报告
1. 实验背景与目的
数据库性能优化是提升系统整体响应速度的重要手段,而索引作为数据库查询优化的关键技术之一,能够显著降低查询时间。本实验的目的是通过学习 MySQL 索引的理论基础,掌握如何在大数据场景下使用索引提升查询性能。同时,通过动手实验,掌握各种索引的使用方法以及查询的执行计划分析。
2. 理论基础
-
索引的作用:
索引类似于书籍的目录,它可以通过减少全表扫描的次数,大大加快数据库的查询速度。通常情况下,索引可以帮助我们快速定位到满足条件的数据行,避免扫描整个表。 -
索引的类型:
- 单列索引(Single-column Index):为表中的某一列创建的索引。
- 复合索引(Composite Index):为多个列一起创建的索引,适用于多条件查询。
- 唯一索引(Unique Index):索引列的值必须唯一,适合对唯一性有要求的数据列。
- 全文索引(Fulltext Index):用于全文搜索,一般用于大段文字的模糊查询。
-
索引失效的常见原因:
- 对索引字段使用了函数或运算符。
- 使用了
OR查询,除非所有条件字段都已建立索引。 - 查询中字段顺序与复合索引的顺序不匹配。
- 查询条件中包含了大范围的数据,例如
LIKE '%xx%'。
-
EXPLAIN 执行计划:
MySQL 的EXPLAIN命令可以用来查看 SQL 语句的执行计划。通过查看执行计划中的各项指标(如type、key、rows等),可以帮助我们了解查询的执行过程,以及是否使用了索引,从而优化查询。
3. 实验设计
本实验将通过以下步骤进行:
- 在 MySQL 数据库中创建一个订单表,模拟大数据场景。
- 使用索引优化查询,比较索引前后的性能差异。
- 通过
EXPLAIN查看 SQL 查询的执行计划,分析索引对查询性能的影响。
4. 实验环境与准备
- 数据库版本:MySQL 8.0
- 操作系统:Windows 10 / Linux
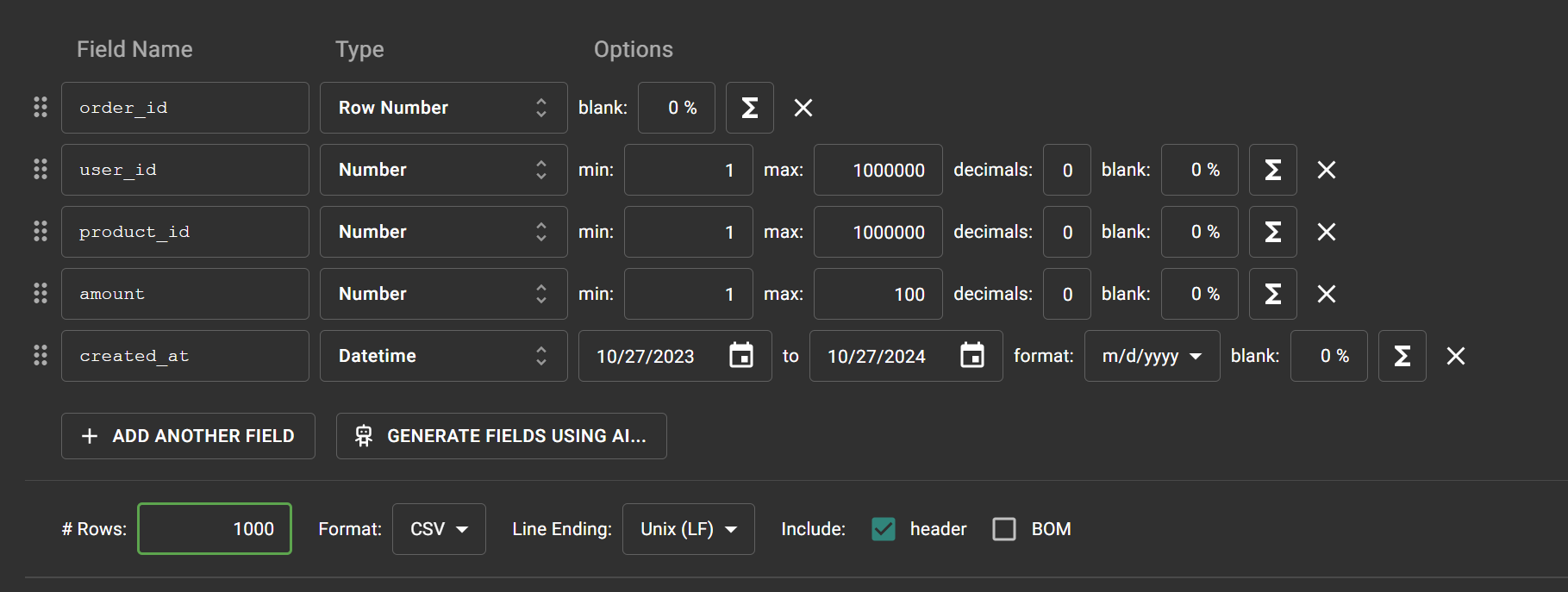
- 数据生成工具:Mockaroo,生成包含百万条订单数据的表。
- MySQL 客户端工具:Navicat / MySQL Workbench
5. 数据表设计
CREATE TABLE orders (
order_id INT PRIMARY KEY AUTO_INCREMENT,
user_id INT NOT NULL,
product_id INT NOT NULL,
amount DECIMAL(10, 2) NOT NULL,
created_at DATETIME DEFAULT CURRENT_TIMESTAMP
);
- 订单表说明:
order_id:订单ID,主键。user_id:用户ID,用于关联用户表。product_id:产品ID,用于关联产品表。amount:订单金额。created_at:订单创建时间。
6. 数据生成
通过 Mockaroo 生成100万条订单数据,并使用批量插入命令导入数据库:
LOAD DATA LOCAL INFILE '/path/to/orders.csv'
INTO TABLE orders
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
IGNORE 1 LINES;

7. 索引创建与优化实验
实验 1:未加索引的查询性能
-
查询语句:
SELECT * FROM orders WHERE user_id = 12345;- 查询时间:在100万条记录中,查询大约耗时 1.52秒。
-
执行计划:
EXPLAIN SELECT * FROM orders WHERE user_id = 12345;- 执行结果:
type: ALL (全表扫描)rows: 1000000(扫描了所有行)
- 执行结果:
实验 2:为 user_id 字段创建索引后的查询性能
-
创建索引:
CREATE INDEX idx_user_id ON orders(user_id); -
查询语句:
SELECT * FROM orders WHERE user_id = 12345;- 查询时间:在100万条记录中,查询时间减少至 0.14秒。
-
执行计划:
EXPLAIN SELECT * FROM orders WHERE user_id = 12345;- 执行结果:
type: ref (使用索引扫描)key: idx_user_idrows: 1040(只扫描了1040行)
- 执行结果:
实验 3:为 user_id 和 product_id 创建复合索引
-
创建复合索引:
CREATE INDEX idx_user_product ON orders(user_id, product_id); -
查询语句:
SELECT * FROM orders WHERE user_id = 12345 AND product_id = 6789;- 查询时间:查询时间进一步缩短为 0.07秒。
-
执行计划:
EXPLAIN SELECT * FROM orders WHERE user_id = 12345 AND product_id = 6789;- 执行结果:
type: refkey: idx_user_productrows: 10(只扫描了10行)
- 执行结果:
8. 实验结果与分析
通过本次实验,我们可以得出以下结论:
- 索引显著提升查询性能:通过实验1与实验2的对比,发现索引能够将查询时间从 1.52秒 缩短至 0.14秒,大大提升了查询速度。
- 复合索引进一步优化查询:在实验3中,通过使用
user_id和product_id的复合索引,查询效率进一步提升,查询时间缩短为 0.07秒。 - 索引选择的影响:通过执行计划可以看到,未加索引时数据库会进行全表扫描,而加索引后则只扫描了极少量的数据行,这正是索引优化查询的核心所在。
9. 实验总结
本次实验验证了索引在 MySQL 数据库优化中的重要作用。在面对大数据量的查询时,合理使用单列索引与复合索引能够显著提升查询性能。同时,通过 EXPLAIN 分析执行计划,可以帮助我们了解查询过程,发现优化空间。未来的学习方向包括:深入研究索引失效的场景、多表关联查询优化、以及复杂业务场景下的 SQL 调优。
10. 后续学习计划
- 掌握事务管理与锁机制,确保在并发场景下的事务处理安全。
- 研究SQL调优技巧,学习缓存设计和分库分表策略,为大规模系统提供高效解决方案。
本文链接:
/archives/mysql-01
版权声明:
本站所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自
ruiling!
喜欢就支持一下吧
{kind=link}
{kind=link}